Introduction
GraphQL is one of the technologies that we like very much at SourceLabs, we even offer GraphQL trainings with Kotlin/Java. Federated GraphQL was a topic that we wanted to explore for a long time and finally for our March meetup, we got to do just that.
Very concise summary of GraphQL
There is a lot to unpack regarding GraphQL, a full day training worth even, for the sake of our topic we will assume that you already have the basics in place and focus on Federated part but in a single sentence: GraphQL is a new way of building APIs with a flexible data unaware query language and execution engine that serves your data model through a single endpoint.
Why GraphQL?
As it always happens in IT, we solve problems with brand new approaches and over time we see that these new solutions have their own drawbacks and come up with solutions to these problems until a need for a whole new approach arises. GraphQL came to be what it is because it addressed the drawbacks of REST APIs. Over time as developers, we saw that, although REST is a great way to define dos and don’ts of APIs for the developers who are building the APIs, it restricted the developers who are the clients of these said APIs.
All the APIs naturally evolved and started to offer more and more data, mostly fields got deprecated and new ones were added to their response models and if there were breaking or major changes, they had to create new versions of APIs such as /v1/resource and /v2/resource. Because of these changes we had to,
- maintain models of our dependencies all the time,
- update our models or upgrade our clients,
- map the new fields or deprecate the old ones,
- create internal models that didn’t exactly match the responses we got which introduced adapter layer complexities.
This is what GraphQL addresses, a single point API for your service that serves all your data where your clients decide and fetch what they need, and as the API evolves your clients stop fetching deprecated fields or start fetching new fields as they please, putting the responsibility of the maintaining the data model in the developers that build the API and be conscious of their own data model.
No drawbacks of GraphQL?
As you can guess from where the story is headed, GraphQL also has its drawbacks! In theory everything seems nice and dandy, for small to mid-size APIs, or microservice architectures where each microservice owns its data and have clear borders in terms of responsibility, GraphQL sounds amazing. But in practice, things are not as straightforward as they seem. Contemporary organizations have complex development environments where multiple teams have to be responsible from certain parts of the same resource, or APIs from different teams depend on each other in order to serve their own resources, or more and more of autonomous teams of these big organizations are moving to GraphQL where clients need both of their resources, or these teams still want to serve specific parts of the “basic” data making your models to have overlapping fields which is one of the very first things that GraphQL wanted to solve.
Any solutions?
But of course, there are different solutions to all the problems we’ve just listed. Most popular of those being stitching and federation. In the community there are many definitions of what stitching is and even many more endless discussions over stitching vs federation, and again for the sake of our content, we will solely focus on federation.
What is Federation?
Federation uses a declarative programming model that makes it easy for each implementing service to implement only the part of their data graph that they should be responsible for, which then all the services should be able to extend each other’s schemas and create one schema that works and makes sense together.
A meetup without coding is like a party without cake
This is where it makes more sense to talk over an example to understand everything better. Introducing our hypothetical company: “Intranet Movie Database”. This company of ours currently has 3 teams. First team is responsible from managing and exposing information about movies, where the second team is responsible for managing and exposing reviews from users that are related to these movies, lastly the third team is responsible from critical articles that are published about these movies on NYTimes. They all love and use GraphQL for their services and all their data model is as follows.
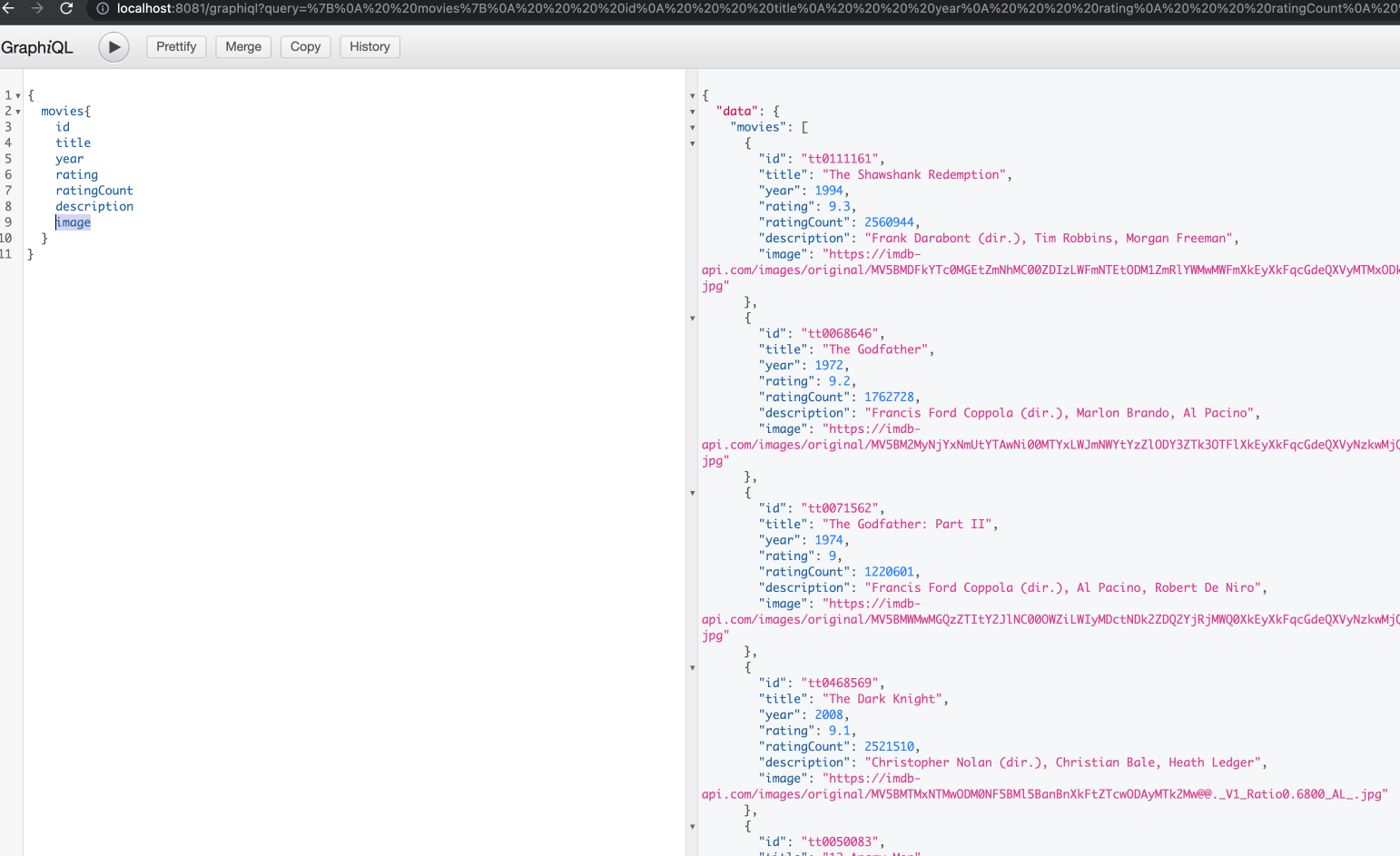
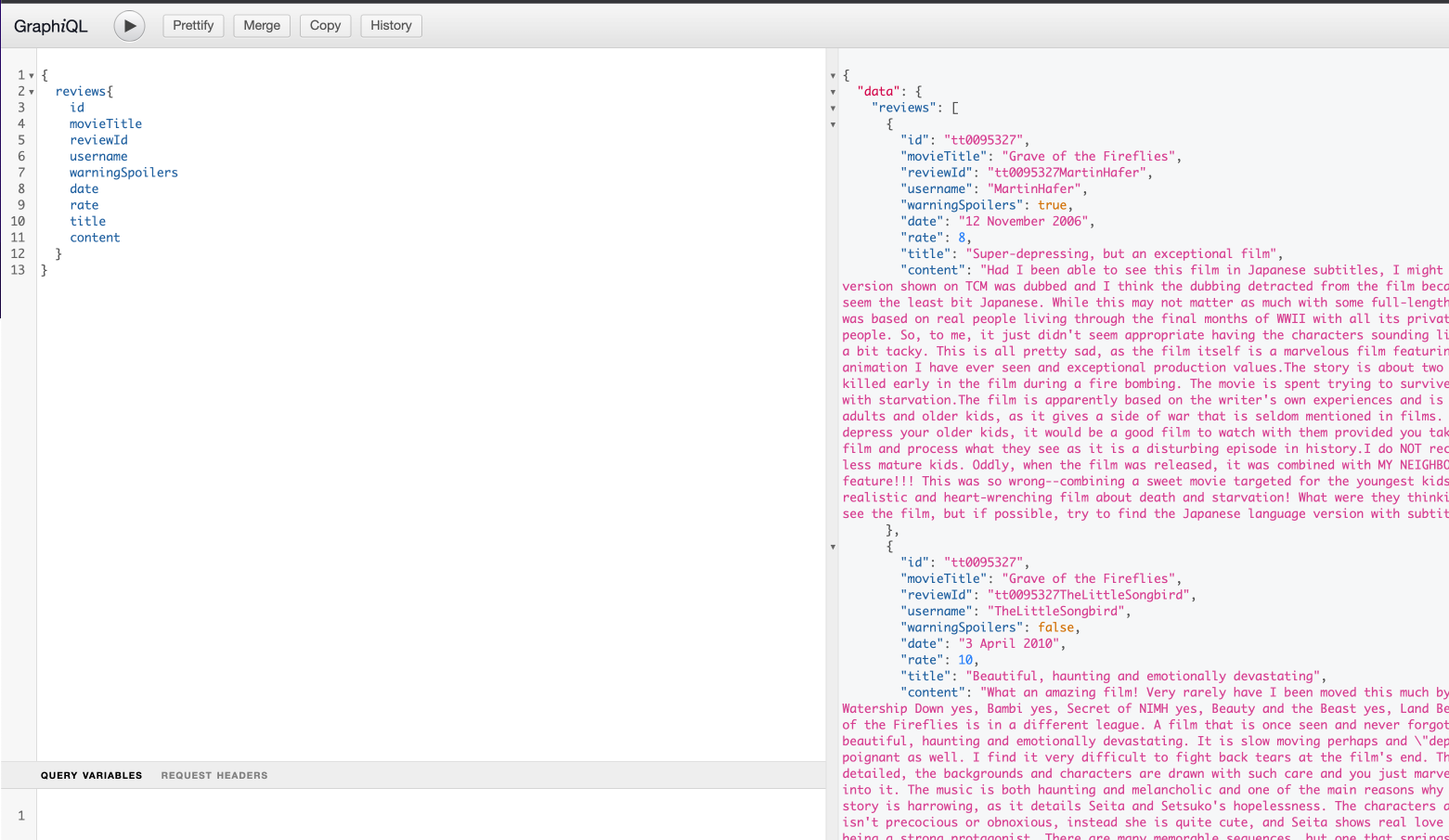
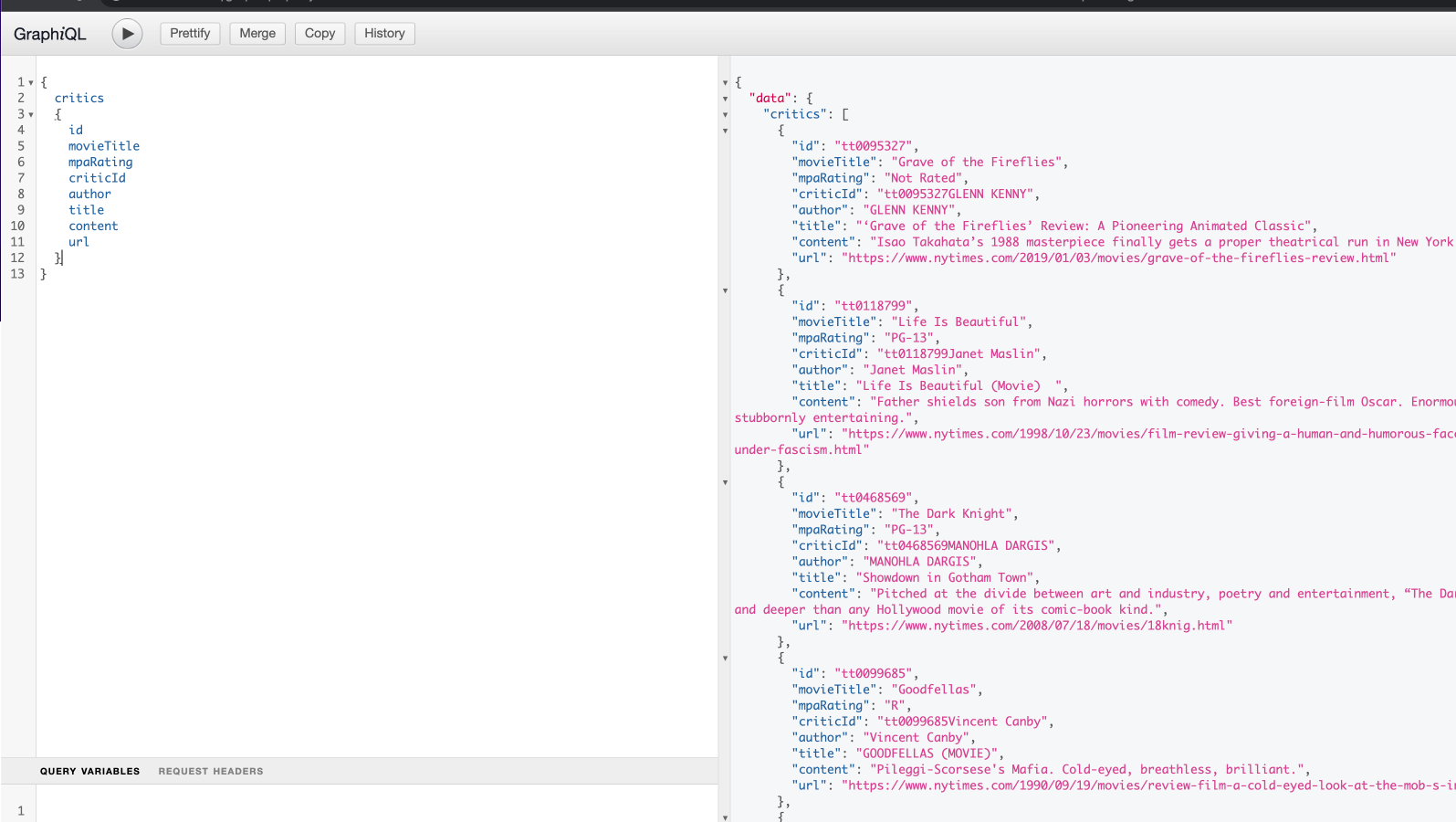
And naturally their GraphQL schemas are as follows
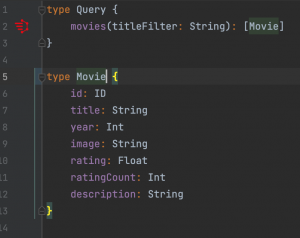
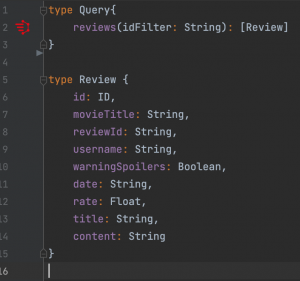
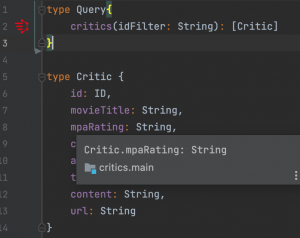
Now first team that is responsible for movies is tasked with exposing all the information about a movie including their critics and reviews. How can they do this? They must create internal fetchers for reviews and critics and put those into their own schema, meaning that they will be responsible for these data that they don’t own. Here comes the federation in play. With federation all these teams can agree on a common foreign identifier, which in our case is the id of the movie that is already shared among these three and include only necessary annotations to their schema so that the federation engine can figure out the rest and create a common schema to serve. Our federation engine, Apollo Server, needs these schema changes:
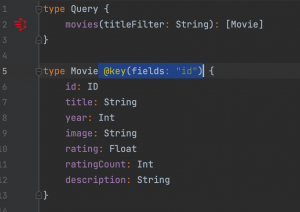
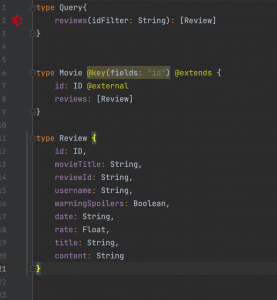
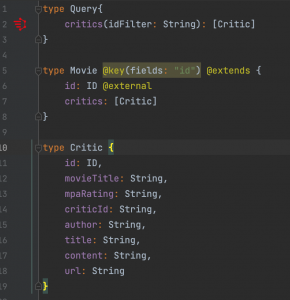
After these changes all we need to set up is our Apollo Server application, which is a node.js application where we just point where GraphQL instances that, we want to be federated, run.
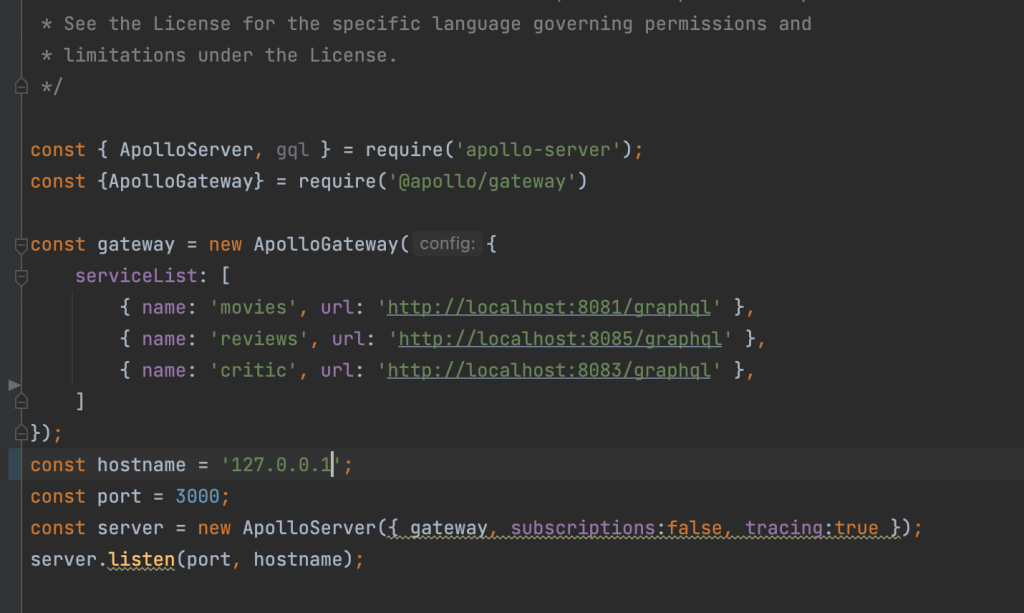
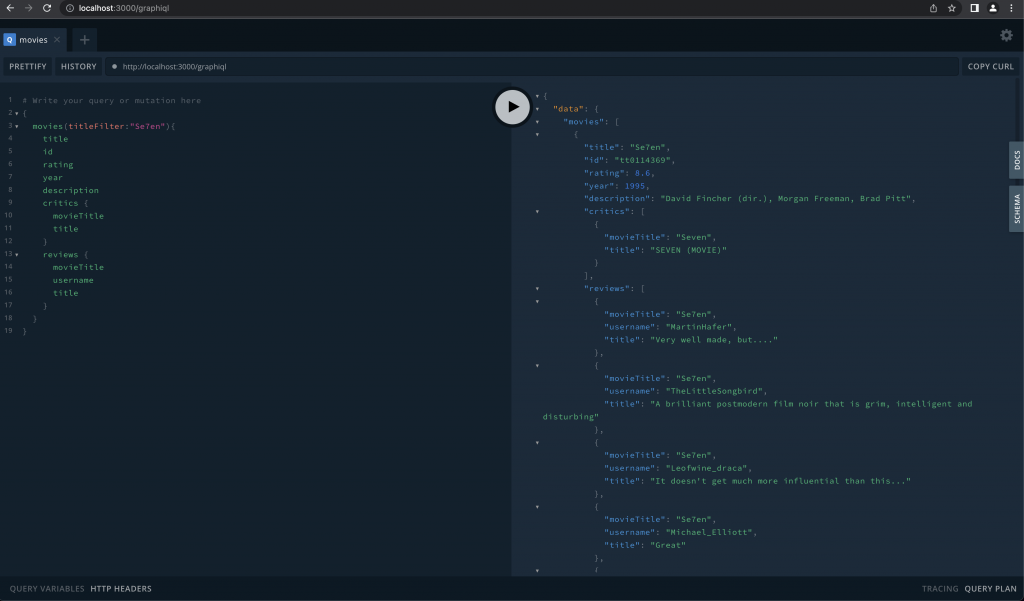
And just like that we have our new federated data model served under Apollo Server
Conclusion
As we previously mentioned, services in complex environments all have their own data that they are responsible for. Although from outside world or from frontend perspective, all the backend systems and data seem like a whole, in practice they are all scattered in manageable pieces that is maintained by autonomous teams that sometimes don’t even share the same programming language or data standards. With Federated GraphQL we get rid of extra layers of complexity that is created by aggregator services or backend for frontends (BFFs) and still keep the teams decoupled and confined in their own responsibilities.
Interested in more?
We have done more in our meetup than what we showcased in this blog post, such as extending our company with a new team that developed a service that manages actor information. And Clients that need specific parts of specific schemas for their needs. If you are interested all codebase and use cases can be found in this github repo.
If you are also interested in a training regarding Federated GraphQL or many more topics that we offer, visit our website and contact us.